找客服
找技术
VIP申请
网站优化可以从狭义或者广义两个方面来说明,狭义的网站优化,即搜索引擎优化(SEO),...
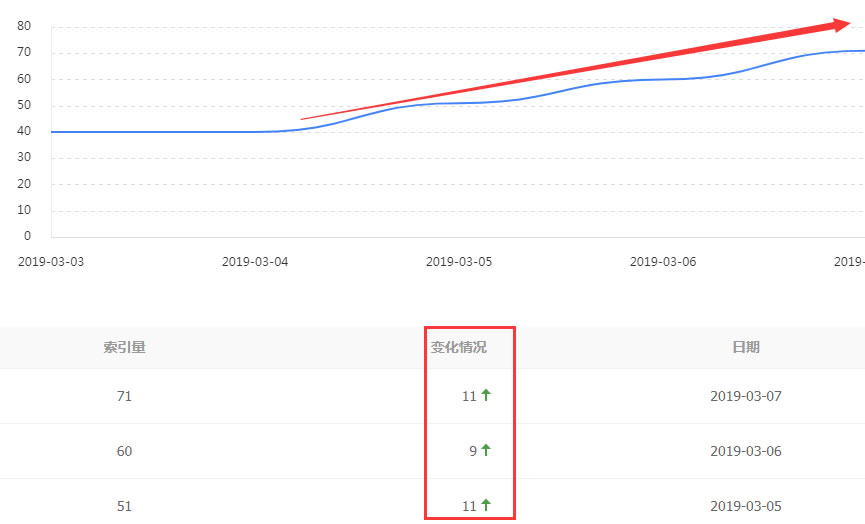
一般所指的网站排名主要可分为几大类,有Alexa网站排名,中国网站排名,百度, NN...
关键词可以从狭义和广义两个方面来说明,狭义的网站优化技术,即搜索引擎优化,也就是让网...
关键词排名优化是指通过各种搜索引擎优化(seo)方式,使您网站的关键词在搜索引擎自然...
搜索引擎优化已经被越来越多的人接受,通过搜索引擎精准获客。想做好搜索引擎优化就要解决...
关注回复 多图文关注回复 默认回复 自定义关键字回复 打招呼回复 扫参数二维码回复 ...
适用类型: 微信公众号 微信小程序 PC 支持: PHP5.6 PHP7.1 PHP...
新站收录困难。新站发布的文章被百度收录也困难,这是为什么?很有可能是网站自身或是...
一对一解决方案
专业从事PHP网站建设5年
满足不同行业,不同建站需求
陈旧网站无法满足
专业提供高端网站设计/前端切图
为您的网站转化率猛增
推荐一些靠谱的云服务器
靠谱的云服务器厂商
100%完美运行各类PHP程序
因为专注 · 所以专业
品牌 创意 服务 技术
PHP 开发工程师
欢迎开发人才加入我们的团队
联系我们,共创美好未来
专业、稳定、品质之选
只提供优质的售后服务
网站排名
网站优化
关键词排名
关键词优化
联系源码哥
直接说出您的需求! 切记!带上资源连接与问题!
工作时间: 9:30-23:30
首页
签到
切换
客服